使用 Unsloth 微调 Google Gemma
前言
将自然语言查询转化为代码是 NLP 领域最艰巨的挑战之一。将一个简单的英语问题转换成复杂代码的能力为开发人员的工作效率和快速软件开发生命周期提供了多种可能性。这就是开源大语言模型 Google Gemma 发挥作用的地方。本指南将探讨如何使用 unsloth 微调 Google Gemma,以便从自然语言查询生成代码语句。

学习目标
- 了解从自然语言生成代码对提高开发人员效率的重要性。
- 了解 Google Gemma 及其在将英文查询转化为代码方面的作用。
- 探索 Unsloth 对大型语言模型的效率提升和内存管理。
- 设置使用 Unsloth 高效微调 Google Gemma 的环境。
- 准备与 Gemma 和 Unsloth 兼容的数据集,以便进行有效的微调。
- 使用 SFTTrainer 掌握使用特定训练参数对 Google Gemma 进行微调的方法。
- 使用微调后的 Gemma 根据自然语言提示生成代码。
- 评估微调后的 Gemma 在软件开发工作流中的性能。
Gemma 简介
Google 开发了一套名为 Google Gemma 的开源大型语言模型。它是在 Google 双子座模型的基础上使用 6T 文本标记进行训练的。这些模型被认为是 Gemini 模型的轻型变体。Gemma 系列有两种规格:用于 CPU 和设备应用的 20 亿参数模型,以及用于 GPU 和 TPU 有效部署的 70 亿参数模型。
Gemma 具有尖端的大规模理解和推理能力,并在文本领域具有很高的天赋。它在各种类别(包括问题解答、常识推理、数学和科学)中的表现都优于其他开放模型,其规模可与之媲美或更大。 Google 为这两种模型的推理和服务发布了微调检查点和开源代码库。在本指南中,我们将使用 Gemma 的 70 亿参数版本。
什么是 Unsloth?
Daniel Han 和 Michael Han 创建了 Unsloth,并迅速成为为完善大型语言模型(LLM)微调过程而量身定制的优化框架。Unsloth 以其敏捷性和内存效率而闻名,其训练速度可提高 30 倍,内存使用量显著减少 60%。这些令人印象深刻的指标使其成为开发人员寻求精确、快速微调 LLM 的首选框架。
值得注意的是,Unsloth 支持不同的硬件设置,包括英伟达™(NVIDIA®)Tesla T4 到 H100 等 GPU,并将其兼容性扩展到 AMD 和英特尔 GPU。该库的适应性得益于其采用的开创性技术,其中包括智能权重上投,该功能可在 QLoRA 过程中减少权重上投的必要性,从而优化内存使用。此外,Unsloth 还能迅速利用 bfloat16,提高 16 位训练的稳定性,加快 QLoRA 的微调。
作为获得 Apache 2.0 授权的开源工具,Unsloth 无缝集成到了 Mistral 7B、Llama 和 Google Gemma 等著名 LLM 的微调中,微调速度提高了 5 倍,同时内存消耗减少了 60%。此外,它还兼容 Flash-Attention 2 等其他微调方法,这不仅加快了推理速度,甚至还加快了微调进程。
设置环境
首先要准备好 Python 环境,下载并安装必要的库。我们将在 Google Collab 上对 Gemma LLM 进行微调。为此,我们将执行以下命令
1 | |
- 这将在 Colab 环境中安装 unsloth 库。unsloth 旁边的 [colab] 告诉 pip 安装程序在 Google Colab 环境中安装其他支持 unsloth 的库。
- 这甚至安装了 HuggingFace 的数据集和转换器库。
1 | |
- unsloth 库中的
FastLanguageModel类为 Google Colab 提供了大型语言模型的优化实现。 max_seq_length表示模型在单个序列中可以处理的最大标记数。Gemma 的最大序列长度是 8192,因此初始化长度也是 8192。dtype指定模型权重和激活所使用的数据类型。load_in_4bit设置为true将以 4 位精度加载模型权重。这可以节省内存并提高某些 GPU 的性能,但可能会略微降低精度。
下载 4 位量化模型并添加 LoRA 适配器
在本节中,我们将首先下载 Gemma 模型:
1 | |
这段代码与 FastLanguageModel 类的
from_pretrained()
方法配合使用,从拥抱脸模型中心加载一个预训练模型。 参数
model_name 显示了我们需要加载的模型名称。
max_seq_length、dtype 和
load_in_4bit 参数传递给 FastLanguageModel
类的构造函数。这些都是我们已经定义的参数。
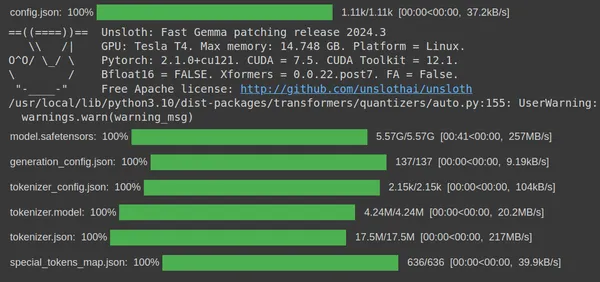
我们可以看到,运行代码后,代码将从 HuggingFace 中的 unsloth huggingface hub 下载 gemma-7b 4 位量化版本。最后,下载量化模型的步骤就完成了。现在,我们需要为此创建一个 LoRA,以便只能训练这些参数的子集。
代码如下
1 | |
r参数决定 LoRA 投影矩阵的秩。它控制着微调所需的参数数量。秩越高,参数越多,性能越好,但模型的内存占用可能会增加lora_alpha选项设置 LoRA 投影矩阵的比例。该参数允许在微调过程中调整学习率。lora_dropout选项用于设定 LoRA 投影矩阵的滤除率。该参数用于减少过度拟合,提高模型的泛化能力。不过,在进行 Unsloth 优化时,该参数设置为0。- 偏置参数决定是否在 LoRA 投影矩阵中包含偏置分量。设置为
"
None" 意味着不应用偏置项。 use_gradient_checkpointing(梯度检查点)变量设置为 "True",以充分利用梯度检查点。这将加快训练过程
最后,运行这段代码将为 Gemma 7B 模型创建 LoRA 适配器,我们可以利用它在不同类型的数据集上对模型进行微调。
为微调准备数据集
现在,我们将下载数据集,准备微调。在本指南中,为了生成代码,我们将使用令牌弯代码说明数据集。该数据集采用 alpaca 类型的聊天格式。数据集如下所示:

我们主要使用 3 列数据,即输入列、指令列和输出列。有了这 3 列数据,我们就可以将其排列成阿尔法卡风格的格式,并在这些数据上训练 Gemma 大语言模型。首先,让我们定义一个辅助函数,用于接收这些数据的每一行,并将其转换为阿尔法卡风格的格式。
1 | |
该函数接收数据集的每一行,并以相应的 Alpaca 格式返回:
- 该函数接收一个参数
x,x代表 DataFrame 的一行。 - 它会检查 DataFrame 行的 "
input" 列中的值是否为 true(if x['input']:)。如果是,它将使用 f-strings 创建一个格式化文本块。 - 如果 "
input" 列为 true,则会构建一个格式化文本块,其中包含指令、输入和响应,每个部分用 markdown 标题(###)分隔。它包括 "instruction" 列中的指令、"input" 列中的输入和 "output" 列中的输出。 - 如果 "
input" 列非真值(为空或求值为 False),则会构建一个类似的格式化文本块,但不包括输入部分。 - 在这两种情况下,格式化文本块的末尾都有一个附加(句末)标记。
- 最后,函数返回构建的格式化文本块。
从 HuggingFace 下载数据集的函数
接下来,我们创建一个从 HuggingFace 下载数据集的函数,并按以下格式转换数据集。
1 | |
load_dataset函数从指定的数据集 ID 中加载数据集并进行分割。to_pandas方法会将数据集转换为 pandas 数据帧。apply方法将lambda函数应用到数据帧中的每一行。lambda函数从每一行中获取指令、输入和输出列,并将它们传递给formatted_train函数。formatted_train函数会返回 Alpaca 格式的格式化聊天模板字符串,我们会将其存储在新的 "formatted_text" 列中。Dataset.from_pandas方法会将数据帧转换回 Dataset 对象。
最后,我们将 data_id 传递给
prepare_train_data 函数。我们从 HuggingFace
下载数据集,对每一行应用指定的更改,然后将生成的 Alpaca
格式文本保存在数据集的 "formatted_text" 列中。
这样,我们就完成了用于微调的代码数据集的准备工作。
微调 Google Gemma 代码数据集
我们现在可以访问数据集进行微调。在本节中,我们将首先定义训练参数,最后对模型进行微调。下面的代码定义了用于微调 Google Gemma 大语言模型的训练参数:
1 | |
所提供的代码片段使用 Transformers 库中的
TrainingArguments
类为大语言模型配置训练参数。这些参数定义了控制训练过程的不同参数。然后将它们与其他训练参数一起传递给
SFTTrainer 类。
关键论点分解
下面是培训论据的关键论据的细目:
per_device_train_batch_size:这表示在每个训练步骤中,每个设备(例如 GPU)处理的训练示例数量。这里设置为 2,即每台设备在每一步中处理 2 个示例。gradient_accumulation_steps(梯度累积步数):定义执行参数更新前的梯度累积步数。通过在多个步骤中累积梯度,可以有效增加批次大小。此处设置为 4,表示在更新模型参数之前,梯度将累积 4 个步骤。warmup_steps(预热步数):设置训练过程中的热身步数,将学习率从 0 逐步提高到所提供的值。这里设置为 5,因此学习率将在前 5 步中线性增加。max_steps(最大步数):这定义了要执行的训练步骤总数。这里设置为 50,意味着训练将在 50 步后停止。learning_rate(学习率):这表示用于训练的第一个学习率。这里设置为 2e-4(2 乘以 10 的-4 次方)。fp16和bf16:这些参数控制训练使用的精度。fp16用于半精度(16 位)训练(如果 GPU 支持),而bf16用于 bfloat16 训练(如果 GPU 支持)。logging_steps(日志记录步数):设置记录训练指标和损失的时间间隔。我们将其设置为 1,因此每训练一步后都会打印日志。optim:用于设置训练时使用的优化器。在这里,我们将其设置为 "paged_adamw_8bit",这是一个专门用于节省内存的优化器。weight_decay(权重衰减):定义正则化所需的权重衰减率。此处设置为 0.01。lr_scheduler_type:用于说明在训练过程中使用哪种学习率调度程序。
通过训练论证
最后,我们完成了训练参数的创建。我们将这些训练参数传递给 SFTTrainer 的 args 变量。除了 TrainingArguments 之外,我们还要传递以下参数:
model:这表示要训练的模型。在我们的代码中,它就是前面定义的模型变量。tokenizer:此处显示用于处理文本数据的标记符。在这里,它是前面定义的 tokenizer 变量。train_dataset(训练数据集):这是训练数据集,是包含格式化文本数据的数据变量。dataset_text_field:此处显示数据集中包含格式化文本的字段名称。此处为 "formatted_text"。max_seq_length(最大序列长度):定义输入和输出序列的最大序列长度。这里设置为 max_seq_length,它是之前定义的一个变量。dataset_num_proc(数据集数目):这是对数据进行标记化处理的工作程序数目。这里的值为 2。packing:这是一个 Bool 值,表示我们是否应该在训练过程中使用序列打包。设置为 false 是因为我们要处理的是较大的数据序列。args:这是之前创建的训练参数对象,其中包含不同的训练参数。
我们终于完成了用于训练量化的 Gemma 7B 大语言模型的训练器的定义。现在,我们将运行训练器开始训练过程。为此,我们要编写以下命令:
1 | |
运行上述程序将启动训练过程。在 Google Colab 中训练该模型可能需要 30 分钟。最后,30 分钟后,将在代码数据集上对模型进行微调:
使用 Gemma 生成代码
现在,我们将测试在代码数据集上经过微调的 Gemma 7B。在此之前,我们先定义一些辅助函数,以便创建 Alpaca 格式的提示。
1 | |
这个函数 format_test()
与我们在数据集处理阶段定义的函数非常相似。唯一不同的是,这次我们只从数据中接收输入和指示,而将输出留给模型来生成。
让我们尝试用这个函数可视化一个提示例子:
1 | |
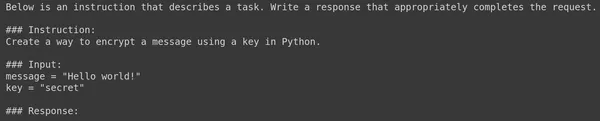
现在,让我们引入微调模型,输入这些信息,看看它会产生什么输出。
Python 代码实现
1 | |
- 从转换器库中导入
TextStreamer类。TextStreamer用于一次一个标记地增量生成文本。 - 使用
FastLanguageModel.for_inference(model)更快地推理语言模型。 - 然后,我们使用预先训练好的标记符对所提供的提示进行标记。然后将标记化后的 Prompt 转换为 PyTorch 张量并移动到 GPU。
- 然后,我们用相同的标记化器初始化一个
TextStreamer对象。 - 我们通过向
model.generate()函数提供text_streamer、输入和最大新标记来生成新文本。 - 运行这段代码将流式显示大语言模型生成的输出。
运行这段代码将流式传输大语言模型生成的输出结果。结果如下
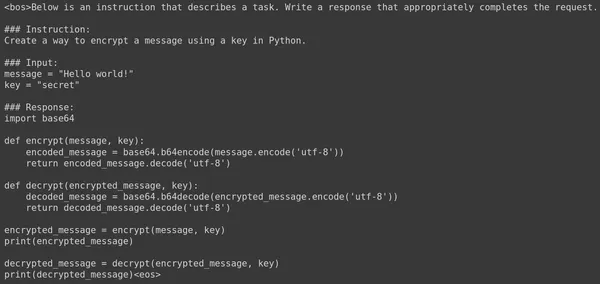
我们看到模型生成了以下代码:
1 | |
由 Gemma 7B LLM 生成的代码工作得非常好。让我们试着问另一个问题,看看生成的答案。下面是经过微调的 Gemma 7B Large Langage Model 生成的另一个提示及其相应的答案。

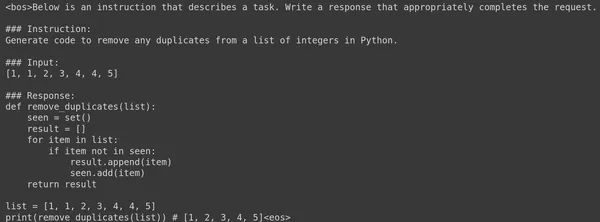
以下是大语言模型为所提供的提示生成的代码:
1 | |
即使是上述代码也能完美运行。我们看到,仅用 60 个步骤对 Google Gemma 7B 大型语言模型进行微调,就生成了一个良好的代码生成模型。LLM 甚至能够正确理解格式,并以相同的 Alpaca 格式生成响应。
结尾
将 Google的 Gemma 与 Unsloth 整合用于从自然语言查询生成代码,在提高开发人员的工作效率方面显示出了潜力。Gemma 是一种强大的大型语言模型,可将英语查询转换为复杂的代码语句,而 Unsloth 则可提高训练效率和内存使用率。这种协同作用增强了自然语言处理(NLP)应用中的代码生成能力,促进了新技术的发展,提高了软件开发效率。
主要收获
- Google Gemma 具有强大的语言理解和推理能力,是代码生成任务的最佳选择。
- Unsloth 是一个用于微调大型语言模型的优化库,可大大提高训练速度、减少内存并提高整体效率。
- 创建环境包括安装必要的库和配置序列长度和数据类型等参数。
- 使用提供的训练参数对 Google Gemma 进行微调,并与 SFTTrainer 类配合使用,有助于在代码数据集上进行高效的模型训练。
- 使用微调后的 Gemma 生成代码时,需要提供 Alpaca 格式的提示,并与 TextStreamer 类配合进行增量文本生成。
- 实际示例表明,经过微调的 Gemma 7B 模型能从自然语言提示中准确生成代码响应,显示了它在改进软件开发工作流程方面的潜力。
使用 Unsloth 微调 Google Gemma

